1. 预备
使用 Hadoop 需要具体一些预备知识: Linux 和 Java;
Linux 可以去看看《鸟哥的私房菜》, Java 不需要太过深入, 看看张孝祥的 《Java 就业培训》就好了.
OLTP: 联机事务处理, 是传统的关系型数据库的主要应用, 主要是基本的、日常的事务处理, 例如银行交易.
OLAP: 联机分析处理, 是数据仓库系统的主要应用, 支持复杂的分析操作, 侧重决策支持, 并且提供直观易懂的查询结果.
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构, 由一套分布式文件系统和一套计算框架构成, 它是一套生态圈, 而不是一个数据库应用.
Hadoop 做的是离线数据分析 (OLAP), 例如像淘宝数据魔方那样统计历史数据; 也正如此 Hadoop 使用的 HDFS 文件系统是个半只读系统, 只支持增加, 不支持修改, 因为历史数据产生了就是产生了, 不需要被修改; 但也有特殊情况存在, 所以 Hadoop 推出了 HBase 这个子项目.
去 IEO: 它是阿里巴巴造出的概念, 其本意是, 在阿里巴巴的 IT 架构中, 去掉 IBM 的小型机、Oracle 数据库、EMC 存储设备, 代之以自己在开源软件基础上开发的系统;
使用 Hadoop 也推崇这个概念, 毕竟 IEO 价格昂贵, 而 Hadoop 可以运行在廉价的 PC 机上.
Hadoop 生产环境选型:

Hadoop 的大多思想都来源于 Google;
Google 技术有三宝: GFS、MapReduce 和 BigTable! HDFS 的灵感就来自 GFS, 而 HBase 的灵感就是 BigTable, 当然也少不了 MapReduce.
Page Rank – 给每个网页评分, 曾是 Google 发家致富的法宝, 是一套非常复杂的算法, 当 Google 收集的网页数量变得非常巨大后, 单台的服务器已经无法完成这个算法的运算, 于是 Google 推出了 Map-Reduce 的方法, 这套方法的中心思想就按某个依据将巨大/复杂的任务拆分、映射到多个服务器进行分布式计算, 最终将各个服务器的运算结果进行汇总.
2. 实验环境
2.1. 条件允许, 可以搞台服务器, 装上 ESXI, 虚拟出几个服务器, 再通过 VMware Client 对其进行管理.
2.2. 如果条件不允许, 可以在本机上用 VMware Workstation (或者 Virtualbox), 推荐虚拟出 3 台服务器, 一台用作 NameNode, 另两台用作 DataNode.
2.3. 还可以在 Windows 上用 cygwin 虚拟出类 UNIX 环境, 不过不推荐这样做…
我们使用 2.2 来进行实验, 参考我的一篇 wiki: 搭建 Hadoop 分布式实验环境
如果使用 2.2 的话, 要去主板的 BIOS 中开启 VT 功能, 能很大的提高虚拟机性能.
3. Hadoop 生态圈
这里仅介绍下几个重要的 Hadoop 子项目;
- Pig, 一种脚本语言, 目的是为了简化 MR 的编写
- Hive, 提供一种类 SQL 语句来操作 MR, 也是为了简化 MR 的编写
- HBase, 这是一个真实的 NoSQL 数据库, 它是为了解决 Hadoop 半只读的问题
像 Pig 和 Hive 都是为了增强 Hadoop 的 OLAP 能力, 而 HBase 是为了增强 Hadoop 的 OLTP 能力.
以上仅为我个人理解, 现在对 Hadoop 接触不深, 可能理解有误, 以后再改进.
4. Hadoop 进程
当 Hadoop 集群跑起来后, 它们产生一些守护进程 (就像在 Windows 系统下的服务一样), Hadoop 是 Java 开发的, 所以这些进程都是 Java 进程, 可以通过 JPS 查看.
Hadoop 集群逻辑上分为两个节点: 主节点 (Master)和从节点 (Slave);
Master 节点为运行着 NameNode、Secondary NameNode 及 JobTracker (ResourceManager) 节点的统称.
Slave 节点为运行着 DataNode 及 TaskTracker (NodeManager) 节点的统称.
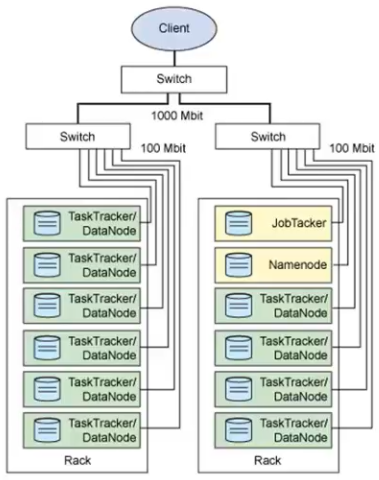
以下先简单介绍, 有个印象, 后续还会单独进行讲解.
4.1 NameNode
- HDFS 的守护程序 (总控), 保存 Hadoop 集群的元数据.
- 记录文件是怎么分块保存的.
- 对内存和 I/O 进行集中管理.
总之就是一个 “老大” 的角色, 在 Hadoop 1.x 中, NameNode 是单点的, 也就是说故障后则整个集群崩溃, 就算有 Secondary NameNode 做为替补, 但也要人工操作, 不能自动替换 (听说在 Hadoop 2.x 中已经支持自动切换了, 暂时没接触过, 还不敢确定).
4.2 Secondary NameNode
就是个 NameNode 的辅助程序, 或者说替补程序, 保存着 NameNode 元数据的快照, 当 NameNode 故障时, 可以用 Secondary NameNode 进行备用.
4.3 DateNode
数据节点守护程序, 简单的说就是 HDFS 保存数据的地方.
4.4 JobTracker
位于 Master 上, 是MR 作业主处理程序, 负责拆分、映射作业到 TaskTracker.
同 NameNode 一样, 它也是个单点进程.
仅为 Hadoop 1.x 上的概念, Hadoop 2.x 上用 ResourceManager 替代了.
4.5 TaskTracker
位于 Slave 节点上, 管理各自的 Task.
仅为 Hadoop 1.x 上的概念, Hadoop 2.x 上用 NodeManager 替代了.
5. CDH
Hadoop 是一套开源框架, 许多公司都推出了各自版本的 Hadoop, 也有一些公司则围绕 Hadoop 开发产品; 在 Hadoop 生态体系中, 规模最大、知名度最高的公司则是 Cloudera (简称 CDH), 类似 Ubuntu 和 Linux 的关系.
后续会对 CDH 进行单独的介绍, 这里仅为了解下是什么就可以了.