所谓的小文件指的是小于一个 block size 的文件.
可选方案
对于尚未上传到 HDFS 的文件, 可以采用以下几种方案:
- 应用程序自己合并文件上传 (要根据实际情况来, 因为上传后不好处理)
- SequenceFile/MapFile, 同样需要自己编程上传文件, 上传的数据将被打包成 k, v 的形式
通常对于 “the small files problem” 的回应会是: 使用 SequenceFile.
这种方法是说, 使用 filename 作为 key, 而 file contents 作为 value.
对于已存在于 HDFS 上的文件, 可以使用:
- Hadoop Archives (HAR files, 类似 zip/rar 的文件归档功能, 打完包后, 需要手动删除被打包前的文件)
- CombineFileInputFormat (MR 的内容)
- HBase compact (HBase 的内容, 把多个 HFile 合并成一个 HFile)
CombineFileInputFormat 及 HBase compact 将在后面的 MR 及 HBase 专题记录, 本篇介绍下 Hadoop Archives.
Hadoop Archives
References:
Hadoop 深入研究: (五) —— Archives
Hadoop 关于处理大量小文件的问题和解决方法
Hadoop Archives (HAR files) 是在 0.18.0 版本中引入的, 它的出现就是为了缓解大量小文件消耗 NameNode 内存的问题.
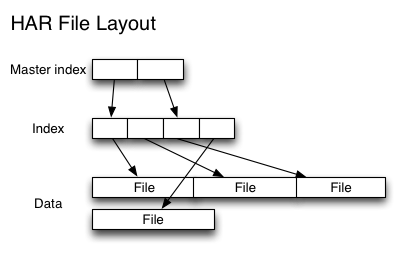
HAR 文件是通过在 HDFS 上构建一个层次化的文件系统来工作, HAR 文件一旦创建便不可再更改.
HAR 文件通过 Hadoop 的 Archive 命令来创建, 而这个命令实际上也是运行了一个 MapReduce 任务来将小文件打包成 HAR.
对于 client 端来说, 使用 HAR 文件没有任何影响, 所有的原始文件都可见&&透明, 但在HDFS端它内部的文件数减少了.
通过 HAR 来读取一个文件并不会比直接从 HDFS 中读取文件高效, 而且实际上可能还会稍微低效一点, 因为对每一个 HAR 文件的访问都需要完成两层 index 文件的读取和文件本身数据的读取 (见上图). 并且尽管 HAR 文件可以被用来作为 MapReduce job 的 input, 但是并没有特殊的方法来使 maps 将 HAR 文件中打包的文件当作一个 HDFS 文件处理.
总结一下就是说 HAR:
- 通过将小文件打包成一个大文件来减少 NameNode 的内存消耗
- 虽然可以 HAR 当成一个包传递成 Map 任务, 但是实际处理时, 并不是将它看作一个文件, 而是以打包前的数据进行处理
创建文件: hadoop archive -archiveName xxx.har -p /src /dest (-p 参数指定要打包的目录和目的地目录)
查看内容: hadoop fs -lsr har:///dest/xxx.har (注意 har:/// 协议)