首先说明 . . . 也许这两个功能你根本不可能用到上, 因为你的集群规模完全达不到要求.
在 1.X 时代, 你可能需要再另外建立一个 Hadoop 集群 . . . 想像一下建立一个集群的成本 . . .
Hadoop 1.x 中, 一个集群就只有一个 NameNode, 这种架构虽然实现简单, 但会产生单点、内存瓶颈、性能 瓶颈等限制.
问题一, 整个 Hadoop 集群的命名空间都归一个 NameNode 管理, 这样 HDFS 所能存储的文件数量会受到 NameNode 容量的限制;
问题二, 当集群进行复杂运算时, 也只有一个 NameNode 在运作, 集群的运算性能也会受到 NameNode 的限制.
问题三, 虽然集群有 Second NameNode 作为辅助节点, 但并不会完成自动切换, 当 NameNode 宕掉时, 还是需要人工去处理.
虽然仅仅在像 Yahoo 和 Facebook 返种规模的大公司才会面对这样的限制问题, 但在 Hadoop 2.x 中, 官方还是给出了解决方案.
HA + Federation 架构图
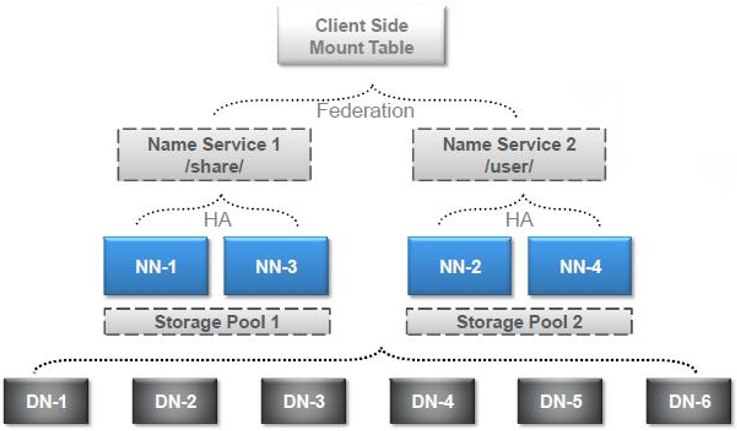
先放张图, 后面的内容将对其进行解释.
Federation (联盟/联邦)
2.X 时代引入了 Federation, 采用 Federation 的最主要原因很简单, 它能够解决上述的 问题一 和 问题二.
Federation 提供了 Hadoop 集群多 NameNode 的能力, 让集群可以水平扩展, 一定程度解决了单 NameNode 的内存瓶颈和性能 瓶颈.
为了水平扩展 NameNode, Federation 使用了多个独立的 NameNode, 有各自自己的命名空间, 他们之间相互独立且不需要互相协调, 各自分工, 管理自己的区域, 不需要和其它 NameNode 协调合作, 但是 DataNode 作为统一的块存储设备被所有 NameNode 共享.
每一个 DataNode 都在所有的 NameNode 进行注册, DataNode 发送心跳信息、块报告到所有的 NameNode 上, 同时呢, 也执行所有 NameNode 发来的命令, 而 NameNode 通过 Block Pools (块池) 对其进行管理.
其实 Federation 主要还是解决了 DataNode 不能被多个 NameNode 共享的问题.
总结下 Federation:
- HDFS 集群扩展性.
- 多个 NameNode 分管一部分目录空间, 使得一个集群可以扩展到更多节点, 不再像 1.x 中那样由于内存的限制制约文件存储数目.
- 性能更高效.
- 多个 NameNode 管理不同的数据, 且同时对外提供服务, 将为用户提供更高的读写吞吐率.
- 良好的隔离性.
- 用户可根据需要将不同业务数据交由不同 NameNode 管理, 这样不同业务之间影响很小.
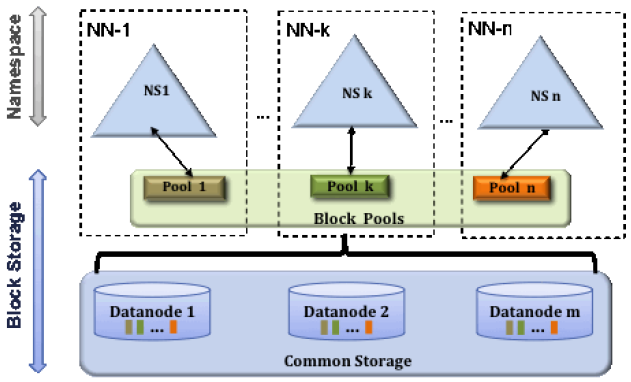
块池
块池是逻辑上的概念, 就是属于单个命名空间的一组块, 它并不是以 DataNode 的个数来划分, 而是将所有的 DataNode 当成一个整体来划分, 所以, 同一个 DataNode 中的块可以被分给多个不同的 Block Pool.
Block Pool 允许一个 NameNode 在不通知其他 NameNode 的情况下为一个新的 Block 创建 Block ID, 但由于 DataNode 会向所有 NameNode 发送心跳及块报告, 所以其它 NameNode 也会知道这个 Block 的使用情况, 这样一个 NameNode 失效就不会影响到其下的 DataNode 为其他 NameNode 继续服务.
当向集群存储数据时, 集群先为其分配 NameNode 创建命名空间, 然后 Block Pools 从 DataNode 上寻找空闲 Block 加入当前 NameNode 所管辖下的块池, 最后 NameNode 将数据存放进这些 Block.
多命名空间的管理问题
为了方便管理多个命名空间, HDFS Federation 采用了经典的 Client Side Mount Table 方式.
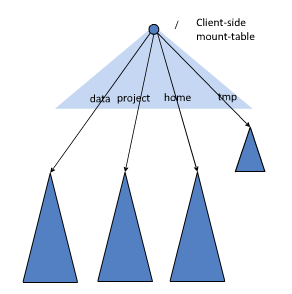
如上图所示, 每个深色三角形代表一个独立的命名空间, 上方浅色的三角形代表从客户角度去访问下方的子命名空间. 各个深色的命名空间 Mount 到浅色的表中, 客户可以访问不同的挂载点来访问不同的命名空间, 这就如同在 Linux 系统中访问不同挂载点一样.
配置 Federation
还没实操过, 需要的时候参考 (主要是 core-site.xml 中 viewfs 及 hdfs-site.xml 中 nameservices 的配置):
Hadoop 2.0 NameNode HA 和 Federation 实践 (为防止链接失效, 我摘到了 OneNote 中: 我的笔记本/Hadoop 拾遗/Hadoop 2.0 NameNode HA 和 Federation 实践)
搭建 Hadoop 2.2.0 HA && Federation (为防止链接失效, 我摘到了 OneNote 中: 我的笔记本/Hadoop 拾遗/搭建 Hadoop 2.2.0 HA && Federation)
需要注意一点的就是, Federation 需要在每个 NameNode 上分别格式化, 第一个 NameNode 可以使用之前的 hdfs namenode -format 命令进行格式化, 格式化后就会产生一个 ClusterId, 剩下的 NameNode 需要指定 ClusterId 进行格式化: hdfs namenode -format -clusterId.
Java API
ViewFileSystem fsView = (ViewFileSystem)ViewFileSystem.get(conf); MountPoint[] m = fsView.getMountPoints(); for (MountPoint m1 : m) { System.out.println(m1.getSrc()); }
2.X 高可靠
Reference: Hadoop2 NameNode HA 原理详解
Hadoop2 NameNode HA 方案让 NameNode 有个备份节点, 当 NameNode 宕掉了, 备份节点就接管 NameNode 的职责.
原理
需要用到集群: JournalNodes.
两个 NameNode 通过 JournalNodes 通信, 共享 NameNode 数据.
NameNode 有两种状态, 一种是激活状态 Active, 另一种是准备状态 Standby;
Active 对外提供服务, 当 Active 数据发生变化, 它会同步到 JournalNodes, JournalNodes 收到变化后同步给 Standby, 当 Active 宕掉, Standby 就可以接管.
接管方式
- 手动接管
- 自动接管, 要通过 FailoverController (故障转移控制器) 去实现, 而 FailoverController 是属于 zookeeper 集群的一部分.